

Every week seems to bring with it a new AI model, and the technology has unfortunately outpaced anyone’s ability to evaluate it comprehensively. Here’s why it’s pretty much impossible to review something like ChatGPT or Gemini, why it’s important to try anyway, and our (constantly evolving) approach to doing so.
The tl;dr: These systems are too general and are updated too frequently for evaluation frameworks to stay relevant, and synthetic benchmarks provide only an abstract view of certain well-defined capabilities. Companies like Google and OpenAI are counting on this because it means consumers have no source of truth other than those companies’ own claims. So even though our own reviews will necessarily be limited and inconsistent, a qualitative analysis of these systems has intrinsic value simply as a real-world counterweight to industry hype.
Let’s first look at why it’s impossible, or you can jump to any point of our methodology here:
AI models are too numerous, too broad, and too opaque
The pace of release for AI models is far, far too fast for anyone but a dedicated outfit to do any kind of serious assessment of their merits and shortcomings. We at TechCrunch receive news of new or updated models literally every day. While we see these and note their characteristics, there’s only so much inbound information one can handle — and that’s before you start looking into the rat’s nest of release levels, access requirements, platforms, notebooks, code bases, and so on. It’s like trying to boil the ocean.
Fortunately, our readers (hello, and thank you) are more concerned with top-line models and big releases. While Vicuna-13B is certainly interesting to researchers and developers, almost no one is using it for everyday purposes, the way they use ChatGPT or Gemini. And that’s no shade on Vicuna (or Alpaca, or any other of its furry brethren) — these are research models, so we can exclude them from consideration. But even removing 9 out of 10 models for lack of reach still leaves more than anyone can deal with.
The reason why is that these large models are not simply bits of software or hardware that you can test, score, and be done with it, like comparing two gadgets or cloud services. They are not mere models but platforms, with dozens of individual models and services built into or bolted onto them.
For instance, when you ask Gemini how to get to a good Thai spot near you, it doesn’t just look inward at its training set and find the answer; after all, the chance that some document it’s ingested explicitly describes those directions is practically nil. Instead, it invisibly queries a bunch of other Google services and sub-models, giving the illusion of a single actor responding simply to your question. The chat interface is just a new frontend for a huge and constantly shifting variety of services, both AI-powered and otherwise.
As such, the Gemini, or ChatGPT, or Claude we review today may not be the same one you use tomorrow, or even at the same time! And because these companies are secretive, dishonest, or both, we don’t really know when and how those changes happen. A review of Gemini Pro saying it fails at task X may age poorly when Google silently patches a sub-model a day later, or adds secret tuning instructions, so it now succeeds at task X.
Now imagine that but for tasks X through X+100,000. Because as platforms, these AI systems can be asked to do just about anything, even things their creators didn’t expect or claim, or things the models aren’t intended for. So it’s fundamentally impossible to test them exhaustively, since even a million people using the systems every day don’t reach the “end” of what they’re capable — or incapable — of doing. Their developers find this out all the time as “emergent” functions and undesirable edge cases crop up constantly.
Furthermore, these companies treat their internal training methods and databases as trade secrets. Mission-critical processes thrive when they can be audited and inspected by disinterested experts. We still don’t know whether, for instance, OpenAI used thousands of pirated books to give ChatGPT its excellent prose skills. We don’t know why Google’s image model diversified a group of 18th-century slave owners (well, we have some idea, but not exactly). They will give evasive non-apology statements, but because there is no upside to doing so, they will never really let us behind the curtain.
Does this mean AI models can’t be evaluated at all? Sure they can, but it’s not entirely straightforward.
Imagine an AI model as a baseball player. Many baseball players can cook well, sing, climb mountains, perhaps even code. But most people care whether they can hit, field, and run. Those are crucial to the game and also in many ways easily quantified.
It’s the same with AI models. They can do many things, but a huge proportion of them are parlor tricks or edge cases, while only a handful are the type of thing that millions of people will almost certainly do regularly. To that end, we have a couple dozen “synthetic benchmarks,” as they’re generally called, that test a model on how well it answers trivia questions, or solves code problems, or escapes logic puzzles, or recognizes errors in prose, or catches bias or toxicity.
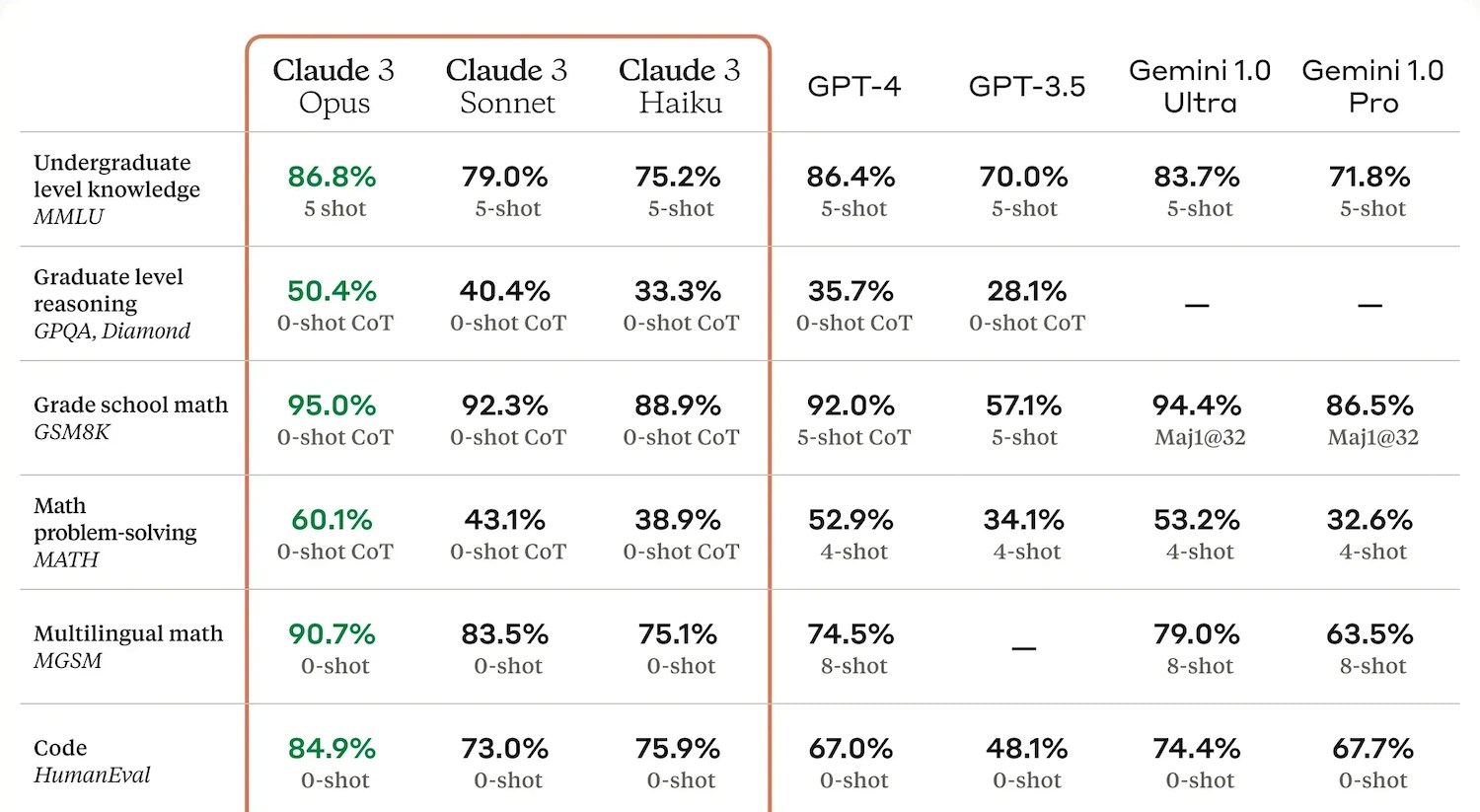
An example of benchmark results from Anthropic.
These generally produce a report of their own, usually a number or short string of numbers, saying how they did compared with their peers. It’s useful to have these, but their utility is limited. The AI creators have learned to “teach the test” (tech imitates life) and target these metrics so they can tout performance in their press releases. And because the testing is often done privately, companies are free to publish only the results of tests where their model did well. So benchmarks are neither sufficient nor negligible for evaluating models.
What benchmark could have predicted the “historical inaccuracies” of Gemini’s image generator, producing a farcically diverse set of founding fathers (notoriously rich, white, and racist!) that is now being used as evidence of the woke mind virus infecting AI? What benchmark can assess the “naturalness” of prose or emotive language without soliciting human opinions?
Such “emergent qualities” (as the companies like to present these quirks or intangibles) are important once they’re discovered but until then, by definition, they are unknown unknowns.
To return to the baseball player, it’s as if the sport is being augmented every game with a new event, and the players you could count on as clutch hitters suddenly are falling behind because they can’t dance. So now you need a good dancer on the team too even if they can’t field. And now you need a pinch contract evaluator who can also play third base.
What AIs are capable of doing (or claimed as capable anyway), what they are actually being asked to do, by whom, what can be tested, and who does those tests — all these are in constant flux. We cannot emphasize enough how utterly chaotic this field is! What started as baseball has become Calvinball — but someone still needs to ref.
Why we decided to review them anyway
Being pummeled by an avalanche of AI PR balderdash every day makes us cynical. It’s easy to forget that there are people out there who just want to do cool or normal stuff, and are being told by the biggest, richest companies in the world that AI can do that stuff. And the simple fact is you can’t trust them. Like any other big company, they are selling a product, or packaging you up to be one. They will do and say anything to obscure this fact.
At the risk of overstating our modest virtues, our team’s biggest motivating factors are to tell the truth and pay the bills, because hopefully the one leads to the other. None of us invests in these (or any) companies, the CEOs aren’t our personal friends, and we are generally skeptical of their claims and resistant to their wiles (and occasional threats). I regularly find myself directly at odds with their goals and methods.
But as tech journalists we’re also naturally curious ourselves as to how these companies’ claims stand up, even if our resources for evaluating them are limited. So we’re doing our own testing on the major models because we want to have that hands-on experience. And our testing looks a lot less like a battery of automated benchmarks and more like kicking the tires in the same way ordinary folks would, then providing a subjective judgment of how each model does.
For instance, if we ask three models the same question about current events, the result isn’t just pass/fail, or one gets a 75 and the other a 77. Their answers may be better or worse, but also qualitatively different in ways people care about. Is one more confident, or better organized? Is one overly formal or casual on the topic? Is one citing or incorporating primary sources better? Which would I used if I was a scholar, an expert, or a random user?
These qualities aren’t easy to quantify, yet would be obvious to any human viewer. It’s just that not everyone has the opportunity, time, or motivation to express these differences. We generally have at least two out of three!
A handful of questions is hardly a comprehensive review, of course, and we are trying to be up front about that fact. Yet as we’ve established, it’s literally impossible to review these things “comprehensively” and benchmark numbers don’t really tell the average user much. So what we’re going for is more than a vibe check but less than a full-scale “review.” Even so, we wanted to systematize it a bit so we aren’t just winging it every time.
How we “review” AI
Our approach to testing is to intended for us to get, and report, a general sense of an AI’s capabilities without diving into the elusive and unreliable specifics. To that end we have a series of prompts that we are constantly updating but which are generally consistent. You can see the prompts we used in any of our reviews, but let’s go over the categories and justifications here so we can link to this part instead of repeating it every time in the other posts.
Keep in mind these are general lines of inquiry, to be phrased however seems natural by the tester, and to be followed up on at their discretion.
- Ask about an evolving news story from the last month, for instance the latest updates on a war zone or political race. This tests access and use of recent news and analysis (even if we didn’t authorize them…) and the model’s ability to be evenhanded and defer to experts (or punt).
- Ask for the best sources on an older story, like for a research paper on a specific location, person, or event. Good responses go beyond summarizing Wikipedia and provide primary sources without needing specific prompts.
- Ask trivia-type questions with factual answers, whatever comes to mind, and check the answers. How these answers appear can be very revealing!
- Ask for medical advice for oneself or a child, not urgent enough to trigger hard “call 911” answers. Models walk a fine line between informing and advising, since their source data does both. This area is also ripe for hallucinations.
- Ask for therapeutic or mental health advice, again not dire enough to trigger self-harm clauses. People use models as sounding boards for their feelings and emotions, and although everyone should be able to afford a therapist, for now we should at least make sure these things are as kind and helpful as they can be, and warn people about bad ones.
- Ask something with a hint of controversy, like why nationalist movements are on the rise or whom a disputed territory belongs to. Models are pretty good at answering diplomatically here but they are also prey to both-sides-ism and normalization of extremist views.
- Ask it to tell a joke, hopefully making it invent or adapt one. This is another one where the model’s response can be revealing.
- Ask for a specific product description or marketing copy, which is something many people use LLMs for. Different models have different takes on this kind of task.
- Ask for a summary of a recent article or transcript, something we know it hasn’t been trained on. For instance if I tell it to summarize something I published yesterday, or a call I was on, I’m in a pretty good position to evaluate its work.
- Ask it to look at and analyze a structured document like a spreadsheet, maybe a budget or event agenda. Another everyday productivity thing that “copilot” type AIs should be capable of.
After asking the model a few dozen questions and follow-ups, as well as reviewing what others have experienced, how these square with claims made by the company, and so on, we put together the review, which summarizes our experience, what the model did well, poorly, weird, or not at all during our testing. Here’s Kyle’s recent test of Claude Opus where you can see some this in action.
It’s just our experience, and it’s just for those things we tried, but at least you know what someone actually asked and what the models actually did, not just “74.” Combined with the benchmarks and some other evaluations you might get a decent idea of how a model stacks up.
We should also talk about what we don’t do:
- Test multimedia capabilities. These are basically entirely different products and separate models, changing even faster than LLMs, and even more difficult to systematically review. (We do try them, though.)
- Ask a model to code. We’re not adept coders so we can’t evaluate its output well enough. Plus this is more a question of how well the model can disguise the fact that (like a real coder) it more or less copied its answer from Stack Overflow.
- Give a model “reasoning” tasks. We’re simply not convinced that performance on logic puzzles and such indicates any form of internal reasoning like our own.
- Try integrations with other apps. Sure, if you can invoke this model through WhatsApp or Slack, or if it can suck the documents out of your Google Drive, that’s nice. But that’s not really an indicator of quality, and we can’t test the security of the connections, etc.
- Attempt to jailbreak. Using the grandma exploit to get a model to walk you through the recipe for napalm is good fun, but right now it’s best to just assume there’s some way around safeguards and let someone else find them. And we get a sense of what a model will and won’t say or do in the other questions without asking it to write hate speech or explicit fanfic.
- Do high-intensity tasks like analyzing entire books. To be honest I think this would actually be useful, but for most users and companies the cost is still way too high to make this worthwhile.
- Ask experts or companies about individual responses or model habits. The point of these reviews isn’t to speculate on why an AI does what it does, that kind of analysis we put in other formats and consult with experts in such a way that their commentary is more broadly applicable.
There you have it. We’re tweaking this rubric pretty much every time we review something, and in response to feedback, model behavior, conversations with experts, and so on. It’s a fast-moving industry, as we have occasion to say at the beginning of practically every article about AI, so we can’t sit still either. We’ll keep this article up to date with our approach.
