
The battle for token speed is intensifying as SambaNova, Cerebras, and Groq push the limits of inference performance. With SambaNova setting records on Llama 3.1 405B, Cerebras delivering unmatched speeds with its WSE-3, and Groq’s LPU challenging traditional GPU makers, the race to dominate inference hardware is heating up.
Recently, OpenAI released o1 series of models with reasoning abilities and capacity to ‘think’.
OpenAI o1 is a perfect example proving that reasoning doesn’t require large models. Today many parameters in current models are dedicated to memorising facts for trivia-like benchmarks. Instead, reasoning can be managed by a smaller ‘reasoning core’ that interacts with external tools, such as browsers or code verifiers
This marks a significant shift towards inference-time scaling in production, a concept focused on enhancing reasoning through search rather than purely through learning. “This approach reduces the need for massive pre-training compute and a significant portion of compute is now allocated to inference rather than pre- or post-training,” said NVIDIA’s Jim Fan.
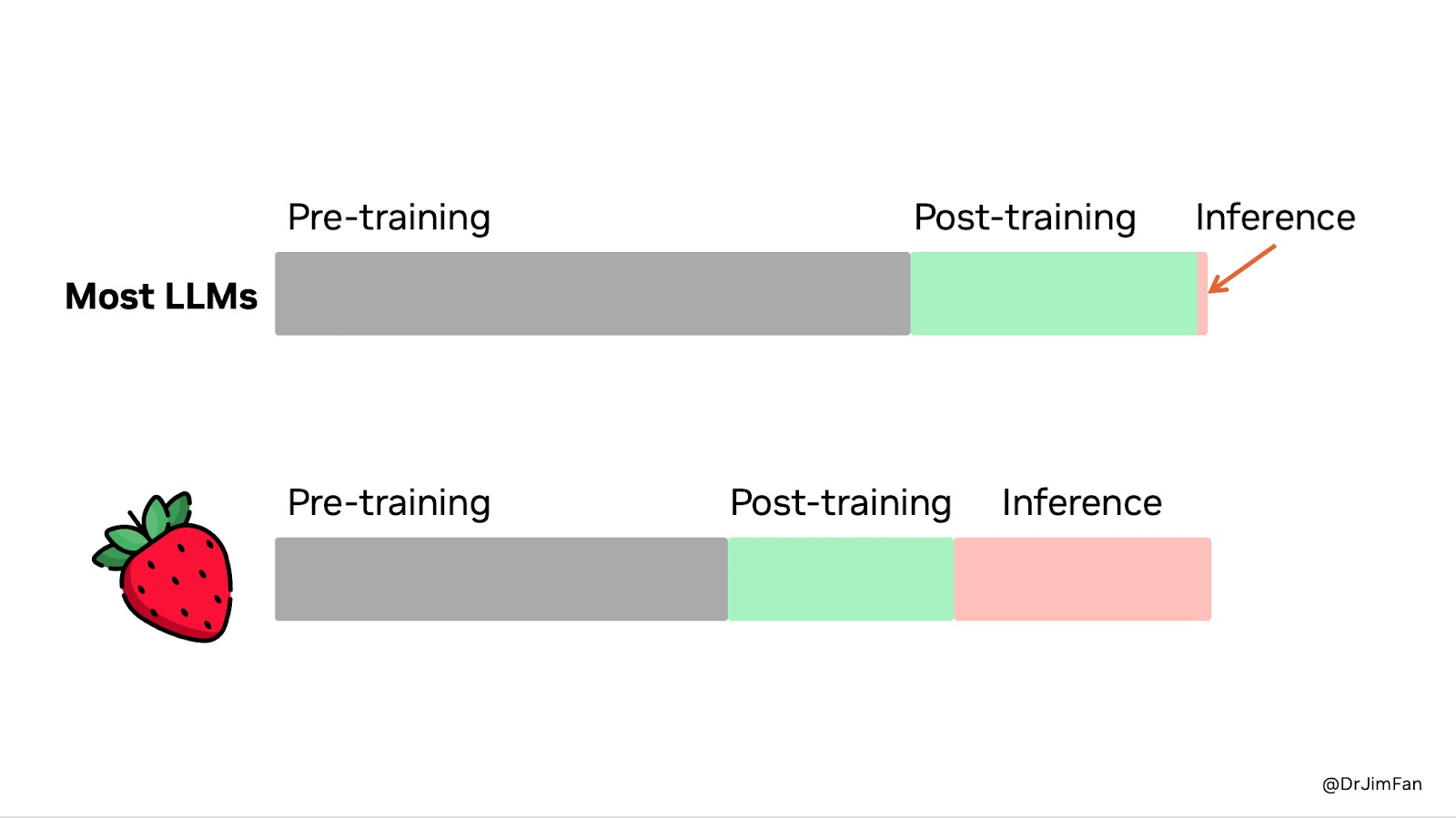
This is good news for the companies like Groq, Cerebras and Sambanova which are currently building inference hardware.
“A paradigm that moves compute from train time to inference time will benefit Groq-style inference hardware,” posted a user on X. Another user commented, “If Meta can release an open implementation of o1, the valuation of companies like Groq could skyrocket.”
Source: X
Battle of Tokens Speed
The LLM inference speed war is heating up. SambaNova recently launched its cloud inference platform, giving developers access to Llama 3.1 models, including the 8B, 70B, and 405B versions, on their custom AI chips. The platform has set a new record for inference on Meta’s Llama 3.1 405B, serving the model in native 16-bit precision and achieving 132 output tokens per second.
The Llama 3.1 70B model runs at 461 t/s. The service is now open to all developers (no wait list required).
Notably, among the three—Groq, Cerebras, and SambaNova—it is the only platform offering Llama 3.1 405B. “The ecosystem around Llama is continuing to push the limits. SambaNova Cloud is setting a new bar for inference on 405B and it’s available for developers to start building today,” posted AI at Meta on X.
“Fast inference is no longer a nice-to-have demo, it will be the driving force behind future frontier models. Time to switch over to custom AI hardware and short NVIDIA,” said Zoltan Csaki, Machine Learning engineer at SambaNova.
The API inference offering is powered by SambaNova’s SN40L custom AI chip, which features their Reconfigurable Dataflow Unit architecture. Manufactured on TSMC’s 5 nm process, the SN40L combines DRAM, HBM3, and SRAM on each chip.
The RDU’s architecture is built around streaming dataflow, which allows multiple operations to be combined into one process, removing the need for manual programming. This delivers faster performance by using a blend of different parallelism techniques, such as pipeline, data, and tensor parallelism, all supported by the hardware.
Cerebras Enters The Fray
Cerebras Inference recently announced that it delivers 1,800 tokens per second for the Llama 3.1 8B model and 450 tokens per second for the Llama 3.1 70B model, making it 20 times faster than NVIDIA GPU based hyperscale clouds.
According to Artificial Analysis Llama 3.1-8B models running on NVIDIA H100 systems across hyperscalers and specialised cloud providers delivered speeds ranging from 72 to 257 tokens per second, with AWS reporting 93 tokens per second for the same workload.
Cerebras Inference is powered by the Cerebras CS-3 system and its advanced AI processor, the Wafer Scale Engine 3 (WSE-3). Unlike traditional GPUs, which require trade-offs between speed and capacity, the CS-3 offers top-tier performance for individual users while maintaining high throughput.
The WSE-3’s massive size allows it to support many users simultaneously, delivering impressive speed. With 7,000 times more memory bandwidth than NVIDIA’s H100, the WSE-3 addresses the core technical challenge of generative AI, memory bandwidth.
Cerebras addresses the inherent memory bandwidth limitations of GPUs, which require models to be moved from memory to compute cores for every output token. This process results in slow inference speeds, particularly for large language models like Llama 3.1-70B, which has 70 billion parameters and requires 140GB of memory.
Cerebras Inference supports models from billions to trillions of parameters. For models exceeding the memory capacity of a single wafer, Cerebras splits them at layer boundaries and maps them to multiple CS-3 systems. Larger models, such as Llama3-405B and Mistral Large, are expected to be supported in the coming weeks.
Nothing like Groq
Groq recently achieved a speed of 544 tokens per second on the Llama 3.1 70B model and 752 tokens per second on the Llama 3.1 8B model, according to Artificial Analysis.
Founded in 2016 by Ross, Groq distinguishes itself by eschewing GPUs in favour of its proprietary hardware, the LPU. The company recently raised $640 million in a Series D funding round, bringing its valuation to $2.8 billion. Most recently, it announced a partnership with Aramco Digital to establish the world’s largest inferencing data center in Saudi Arabia.
Groq’s LPU challenges traditional GPU makers like NVIDIA, AMD, and Intel, with its tensor streaming processor built solely for faster deep learning computations. The LPU is designed to overcome the two LLM bottlenecks: compute density and memory bandwidth.
In terms of LLMs, an LPU has greater compute capacity than a GPU and CPU. This reduces the amount of time per word calculated, allowing text sequences to be generated much faster.
Additionally, eliminating external memory bottlenecks enables the LPU inference engine to deliver orders of magnitude better performance on LLMs compared to GPUs.
The LPU is designed to prioritise the sequential processing of data, which is inherent in language tasks. This contrasts with GPUs, which are optimised for parallel processing tasks such as graphics rendering.